Data Labeling
Driven by an intense desire to understand data and fueled by the opportunities presented during the COVID-19 pandemic, I enthusiastically ventured into the vast world of Python, Machine Learning, and Deep Learning. Through online courses and extensive self-learning, I immersed myself in these areas. This led me to pursue a Master's degree in Data Science. To enhance my skills, I actively engaged in data annotation while working at Biz-Tech Analytics during my college years. This experience deepened my understanding and solidified my commitment to this field.

Introduction to In-House Data Labeling
Data annotation, often called data labeling, is a cornerstone of the AI integration pipeline. It acts as the bridge between the raw data and a functional ML model. The annotators or automated tools add labels or tags to the collected data, helping the model to understand the underlying structure and meaning of the data.
Data Labelling
Mostly, the data are labeled with relevant information to create a labeled training dataset. If you are building a computer vision project, you must deal with the images and videos. Here, the types of data annotation can be used:
Image Categorization
Semantic Segmentation
2D Bounding Boxes
Cuboids
Polygonal Annotation
Key-point Annotation
Object Tracking
If you are dealing with the NLP project, the following are the types of text annotation where the annotators possess the proper linguistic knowledge:
Text Classification
Optical Character Recognition
Named Entity Recognition
Intent Analysis
Transcription

How Does Data Labeling Work?
Most Machine Learning models use supervised learning, where an algorithm maps inputs to outputs based on a set of labeled data by humans. The model learns from these labeled examples to decipher patterns in that data, emphasizing the importance of investing time and resources in accurate data labeling.
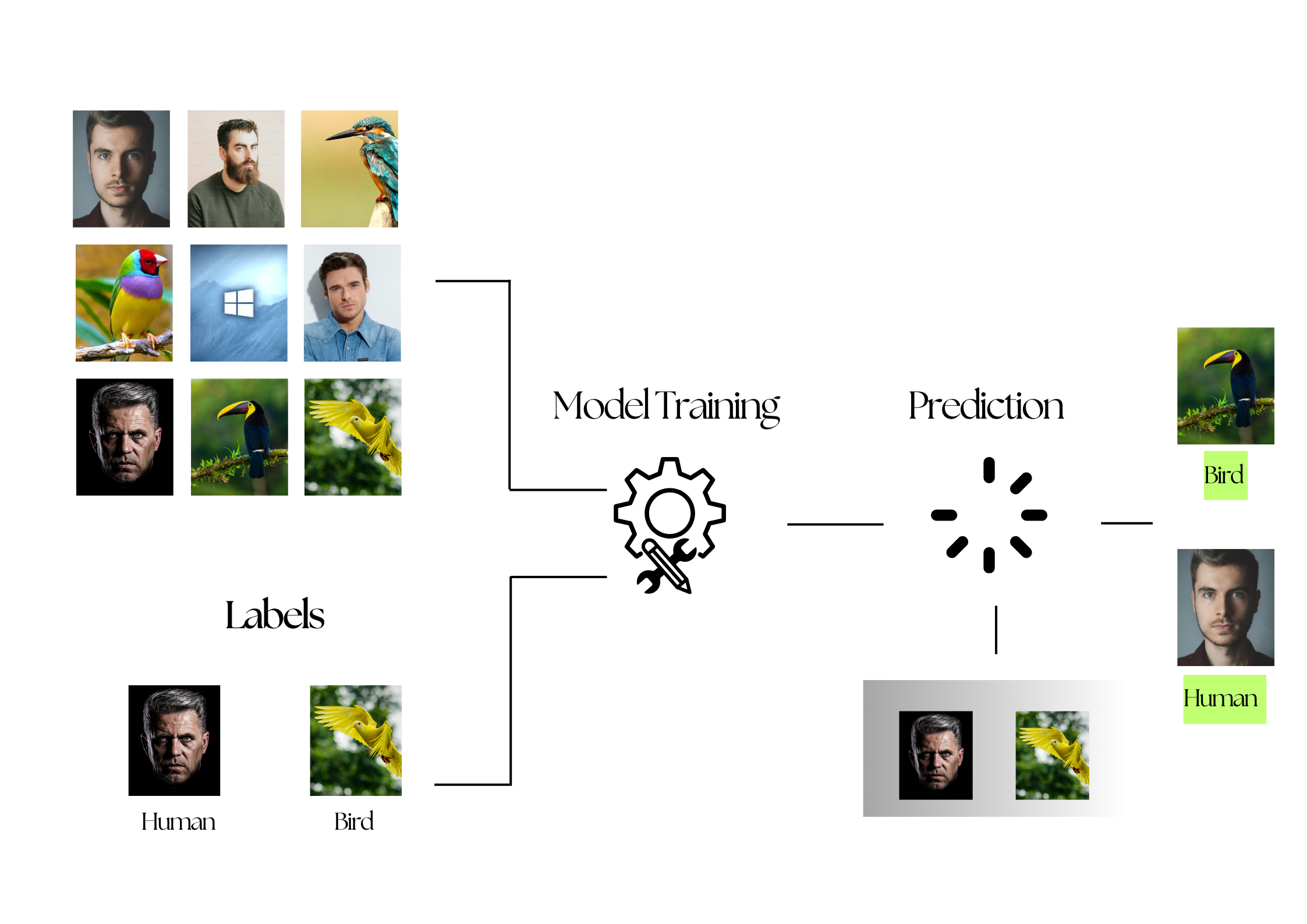
This labeled data is then used to train a machine learning model to find “meaning” in new, relevantly similar data. Throughout this process, machine learning practitioners strive for both quality and quantity. Accurately labeled data, coupled with a larger quantity creates more useful deep learning models, as the resulting machine learning model bases their decisions on all the labeled data.